Was this page helpful?
X Cloud Clusters¶
Overview¶
If you choose the X Cloud option during cluster creation, the better tablets-based data replication in your cluster is enforced on all keyspaces. Owing to tablets, X Cloud clusters provide better elasticity, fast automatic scaling, and allow you to reach up to 90% storage utilization.
X Cloud doesn’t yet support multi-datacenter (multi-DC) deployments. We are actively working to add multi-DC support in an upcoming release.
X Cloud Auto Scaling¶
The serverless architecture behind X Cloud is designed to deliver performance, scalability, and cost efficiency without operational overhead. It automatically ensures your cluster has the right level of resources at the right time, eliminating the need for manual over-provisioning or the risk of underutilization.
With X Cloud, you no longer need to manage capacity planning, manual scaling, or complex cluster rebalancing. This allows your team to focus entirely on building applications while the infrastructure manages itself.
X Cloud clusters scale automatically within a selected instance family, using a mix of instance sizes. The system dynamically adjusts cluster capacity as storage demand increases or decreases, providing several key benefits:
Avoids over-provisioning by continuously aligning capacity with real-time demand.
Enables up to 90% storage utilization, maintaining performance while minimizing cost.
Accelerates scaling—thanks to the tablet-based architecture, new nodes are added in parallel and rapidly rebalanced.
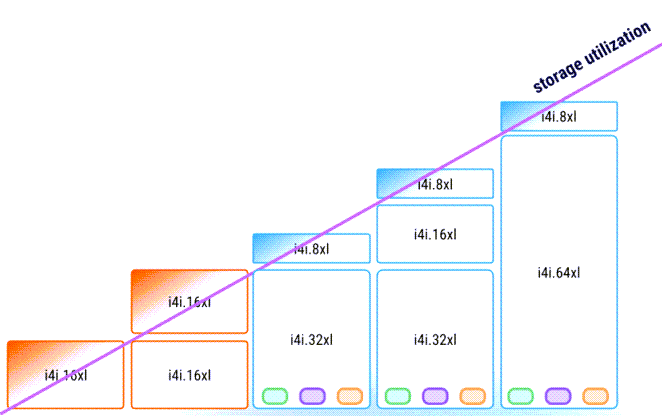
X Cloud clusters are auto-scaled within one predefined instance family, but with different instance types to ensure optimal storage utilization. See Scaling Policy for details.
Auto Scaling Policy¶
When creating an X Cloud cluster, you define an initial auto-scaling policy, which can be updated at any time.
To configure the auto-scaling policy during cluster creation, navigate to the Data Center Scaling Policy section in the X Cloud UI.
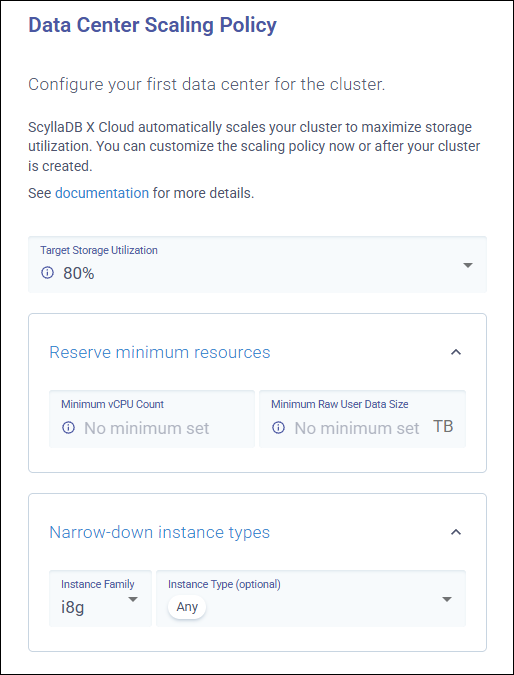
Target Storage Utilization¶
The Target Storage Utilization option defines the specific storage usage level the system aims to maintain. ScyllaDB Cloud monitors metrics and triggers scaling actions to stay as close to your target as possible.
Default: 80%
Maximum: 90%
We recommend adjusting this value based on your specific workload requirements:
For write-intensive workloads, we recommend values below 85% to ensure timely scaling and avoid performance degradation related to scaling in the last possible moment.
While higher utilization optimizes costs, it may throttle operations while scaling under load. For critical production workloads, lower targets provide a larger safety buffer for sudden spikes.
For example, with an 80% target, X Cloud will proactively add capacity as you approach that threshold and remove it when demand drops. For more technical details, see X Cloud Autoscaling Behavior and Best Practices.
Reserving Minimum Resources¶
The Minimum Physical Storage and Minimum vCPU Count fields are optional. You can leave them empty and allow ScyllaDB Cloud to scale resources dynamically based purely on workload.
However, if you have specific capacity requirements, you can set these minimum values to reserve capacity for anticipated load. Setting minimums ensures a baseline level of resources for your workloads. If your cluster is below the defined minimum capacity, it will scale up to meet those requirements. If the cluster is above the set minimums, it will not scale below this baseline. As a result, critical workloads remain stable even when traffic fluctuates.
These minimums can be adjusted at any time.
You can use the built-in calculators to get guidance on appropriate minimum compute and storage capacity values for your cluster. The calculators are designed to help you estimate the resource requirements for your cluster and suggest suitable minimum values.
📱 Minimum Physical Storage Calculator¶
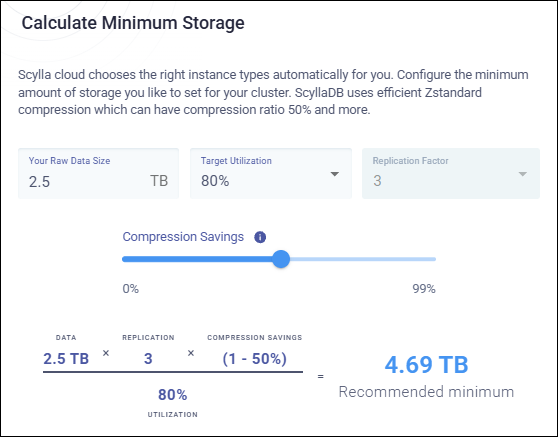
The storage calculator helps you estimate the minimum physical storage required based on the amount of data you plan to store at the start. It uses several factors to calculate the recommended minimum storage.
Raw Data Size - The amount of data you have or expect to store in your cluster. It represents the size of your dataset before replication and compression.
Replication Factor - X Cloud stores the data in three cluster zones, and recommends a fixed replication factor of 3. This means that your data is always stored in three copies across the cluster. This creates three replicas of the data, one in each cluster zone. The total size of the data stored is multiplied by 3:
Raw Data Size × 3.Compression Savings - ScyllaDB Cloud compresses the data, which reduces the actual disk usage. Compression Savings is the total storage space space saved as a result of the compression.
The slider represents how effectively your data can be compressed, which depends entirely on your data type. The examples below show typical compression savings for different data types:
High compressibility (50–80%) - Text-heavy data, such as logs, CSV, JSON or plain text documents
Medium compressibility (30–60%) - Mixed data types, such as typical application data with a combination of text and binary fields, database, backups, snapshots.
Low compressibility (0–20%) - Already compressed data, such as binary data (images, videos) or encrypted data.
Target Utilization - Defines the goal for cluster storage utilization. Autoscaling targets this level of storage utilization by scaling the cluster up or down as needed. This ensures there is always enough storage capacity to handle data,compaction, repairs, and workload spikes without running out of space, minimizing storage underutilization to reduce costs.
The calculator combines these factors to compute the recommended minimum physical storage for your cluster, using the following formula:
((Raw Data Size × 3) × (1- Compression Savings)) ÷ Target Utilization
📱 Minimum vCPU Count Calculator¶

The vCPU calculator helps you estimate the minimum number of vCPUs required to handle your workloads. It uses several factors to calculate the recommended minimum compute capacity for your cluster.
Instance Family - The instance family you can choose for your cluster. It affects can be handled by each vCPU. Different instance families have different performance, and they can handle different ops per second. You can view the estimated ScyllaDB-specific performance next to each instance family name in the UI.
Reads per Second - The number of read operations of your workload. More operations typically require more vCPU resources to maintain low latency and high throughput.
Writes per Second - The number of write operations your workload is expected to perform. More operations typically require more vCPU resources, to maintain low latency and high throughput, especially if they involve complex operations.
Schema Complexity - Adjusts the calculations for individual complexity of your data model and queries. More complex schemas and queries can increase the computational load on the cluster, requiring more vCPU resources to maintain performance. Choose the option that most closely matches your schema:
Simple– No indexes, up to 5 columns, basic queries.Moderate– Includes a single advanced feature such as a secondary index, materialized view, or CDC.Complex– Uses lightweight transactions (LWT) or multiple advanced features.
Instance Family and Type¶
The Instance Family and Instance Type options allow you to narrow down the instances to be used for auto-scaling:
Instance Family - Specifies the instance family to be used. X Cloud clusters are scaled automatically within one predefined instance family.
Instance Type - Specifies instance types to be used for auto-scaling. By default, any instance type within a given family can be used when auto-scaling a cluster to optimize storage utilization and compute.
ℹ️ Manually restricting the cluster to specific instance sizes can limit the effectiveness of the autoscaling engine. We strongly recommend using the default
Anysetting to allow the system to choose the most efficient instance types for your current scale.
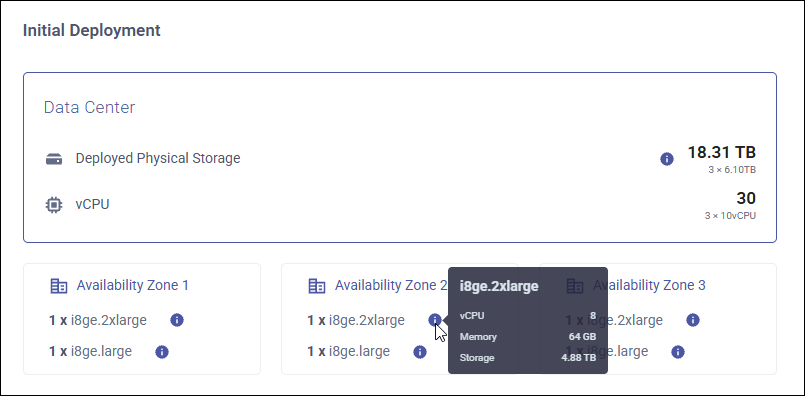
Initial Deployment Summary¶
After you customize the auto-scaling policy, the Initial Deployment summary will be displayed. This is an estimate of what your actual cluster will look like.
Deployed Physical Storage - The total initial amount of physical storage allocated to all nodes in the cluster. If there are changes in storage, the cluster can scale to handle them.
vCPU - The number of vCPUs.
Availability Zones - The availability zones with the instance type configuration for each zone. The cluster consists of three zones with automatic data replication, each with the same instance type configuration. By default, each cluster zone is deployed in a different cloud availability zone. You can customize the availability zones for your cluster, but we recommend that you deploy each zone in a different cloud availability zone to ensure high availability. See Configure Availability Zones for details.
Updating Auto-Scaling Policy for an Existing Cluster¶
To modify the auto-scaling policy for an existing cluster, go to your cluster’s page and click Edit Scaling Policy.

Replication Factor (RF)¶
When using certain ScyllaDB features, the RF must be set to match the number of racks in ScyllaDB Cloud. ScyllaDB Cloud is configured with three racks, so the RF should be set to 3 when using these features.
The features that require this configuration are:
Materialized Views (MV)
Secondary Indexes (SI)
Alternator
CDC